We're seeing application issues (Veeam) due to revocation checks failing on our LE SSL certificates. It appears to maybe relate to [r3.o.lencr.org] being down at present?
Maybe the incorrect SSL certificate on that site?
Anyone else aware of this, any ETA or knowledge by Lets Encrypt of this issue being investigated?
Yeah, ssllabs can't seem to connect to it for quite some time (I think I've seen reports on this forum for weeks about it), though I don't know if it's because one end or the other is blocking it.
I don't see any problems checking OCSP through crt.sh.
You probably need to be clearer about what actual problem you're seeing, including the domain/certificate.
This isn't a bug in SSL Labs. Akamai is legit presenting a bad cert for r4.o.lencr.org which is resulting in global SSL certificate errors. Does anyone know if Let's Encrypt is engaging with Akamai to fix it?
The OCSP info embedded into certificates is a http: link, not https:, so I don't see how Akamai could be serving a certificate for it? And R4 hasn't issued any certificates ever, so why are you looking at the R4 OCSP? I don't see any issues from my side connecting to http://r3.o.lencr.org. Again, can you be really clear about what problems you're seeing? Maybe include steps to reproduce with openssl or other tools?
Agreed, I couldn't see any issues with curl either. I can't pinpoint the root cause as such; other than tell the symptoms (Java isn't very forthcoming with details).
All of the affected applications in our case are JRE 1.8.0; specifically:
openjdk version "1.8.0_292"
OpenJDK Runtime Environment (build 1.8.0_292-8u292-b10-0ubuntu1~20.04-b10)
OpenJDK 64-Bit Server VM (build 25.292-b10, mixed mode)
And are trying to communicate with a service which has a letsencrypt cert on the frontend.
We're working to re-rollout the affected applications with disabled OSCP validation, but i'd rather not really. Annoyingly, java doesn't seem to be falling back to CRL verification for this issue.
It appears (from other people's reporting about the error you've seen, but in another context) that OpenJDK can emit this error (a java.security.cert.CertPathValidatorException: Certificate does not specify OCSP responder) when it's not actually the cause at all.
The text of that error suggests it is examining a certificate which it wanted to see an OCSP responder listed in, and the certificate doesn't have one. But the certificates haven't changed (as you say it's Friday)
Misleading error messages are a pain, but I thought I'd highlight this result of some trawling because it's possible that something quite different is wrong and knowing the error could be wrong might help you find that.
For me, most of my systems aren't noticing the issue except for things connecting to MongoDB using a LE cert. Worked fine until ~4pm ET today when everyone else started reporting it and no changes were made on my side to cause it. Happening both on systems that I use LE certs on as well as cloud services we connect to that are LE.
OK so, we've had two of our locations have spontaneously recovered without us doing anything (South Africa + Brazil); so.... maybe someone is rolling out a fix somewhere? Starting with less-prime sites?
Thanks for posting about this, and we're sorry about the trouble. We just identified and fixed the problem, and created a retroactive status report. The short version is that although our OCSP responder was working correctly, there was another validation problem for some clients: the CRL.
To summarize and confirm some ways troubleshooting in this thread was tricky:
SSL Labs does tend to incorrectly report OCSP failures. In this case, OCSP was working fine.
OCSP is always served over HTTP, so a mismatched TLS certificate at the edge CDN won't cause any failures.
The JRE's exception messages can identify the wrong type of validation failure entirely.
This was also unfortunate timing for us. The start of the incident (that is, the previous CRL's expiration) coincided with our troubleshooting a database performance problem. We didn't believe it was affecting more than a tiny fraction of OCSP requests - so few that it didn't reach our threshold to declare an incident - but our initial troubleshooting efforts assumed that it was related.
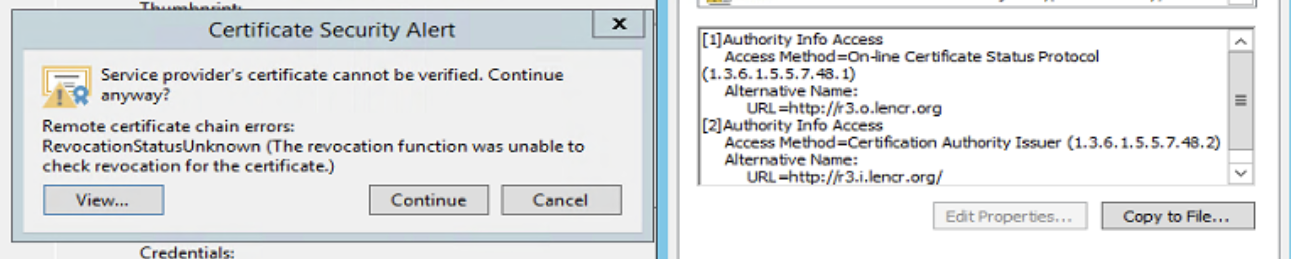
Just to add info. The issue also affected all .NET SslStream connections which were using the default RemoteCertificateValidationCallback. The callback would give sslPolicyError=RemoteCertificateChainErrors accompanied by ChainStatus with the following statuses
RevocationStatusUnknown "The revocation function was unable to check revocation for the certificate."
OfflineRevocation "The revocation function was unable to check revocation because the revocation server was offline."
We had about 45 satellite servers go down simultaneously for a period of about 4.5 hours. We were really thrown by the fact that there was no indication of an issue on https://letsencrypt.status.io/ That along with browsers being unaffected lead us to think it was some kind of weird issue in the guts of dotnet.
We didn't find this thread until after the fact but it is quite a relief to see it acklowledged and explained. Thanks!
At 00:15 (Berlin) I had a terrible problem in my system (Server-Daten with customers). The webserver was ok, but the DbServer wasn't able to send mails to the smtp server running on the webserver.
With a curious error message - "Could not establish a ssl connection".
Checked logs, that started 21:45 (that's 2021-04-30 19:41 - 2021-05-01 00:04 UTC).
Two reboots later and a changed configuration (added some registry keys) it worked.
But that was 02:05 (00:05 UTC).
Ok, so I know, it wasn't a local problem.
Yep, that's my situation. Must check it next day. Normally, I don't want to ignore certificate errors.
Thanks for the update. Just so people are clear, was this some sort of failure on the part of IdenTrust, which would affect any system that checked the CRL signed by DST Root CA X3 of the validity of Let Encrypt's R3 (when using the R3-signed-by-DST chain)? Is there not already monitoring around CRL (and OCSP) expirations?
I'm guessing that the cause of error message some people were seeing around certificates not having OCSP were that R3-signed-by-DST only has a CRL listed, so when that failed the system was hoping to use OCSP instead but couldn't because there was no OCSP for that certificate? It'd sure be helpful if more system error messages said exactly which certificate was having the problem (as I was looking at end-entity certs when it doesn't seem like they were the ones with the problem), but it's amazing how error messages seem to always tell you bazillions of details but never the one detail that would actually help you.
 )
)